Automated FAQ Mining for Support Chatbots
01 — Project objective
*Prototype — automation logic validated, refinement in progress
Build an automated pipeline that ingests website content, extracts relevant text, generates semantic embeddings, and stores structured knowledge for use in AI search and FAQ systems.
02 — Problem
Companies publish large volumes of product documentation and support content. Transforming this text into an AI-ready knowledge base (for RAG, semantic search, and chat assistants) is often done manually, which is slow and inefficient.
The goal was to automate this process end-to-end.
03 — Solution Overview
I designed an n8n workflow that:
- Fetches new content from a chosen source (Stripe documentation example)
- Extracts readable text from HTML
- Cleans and splits content into semantic chunks
- Generates embeddings using a language model
- Stores text and vector data for later retrieval
This creates a scalable internal knowledge pipeline suitable for AI-powered search and automated FAQ responses.
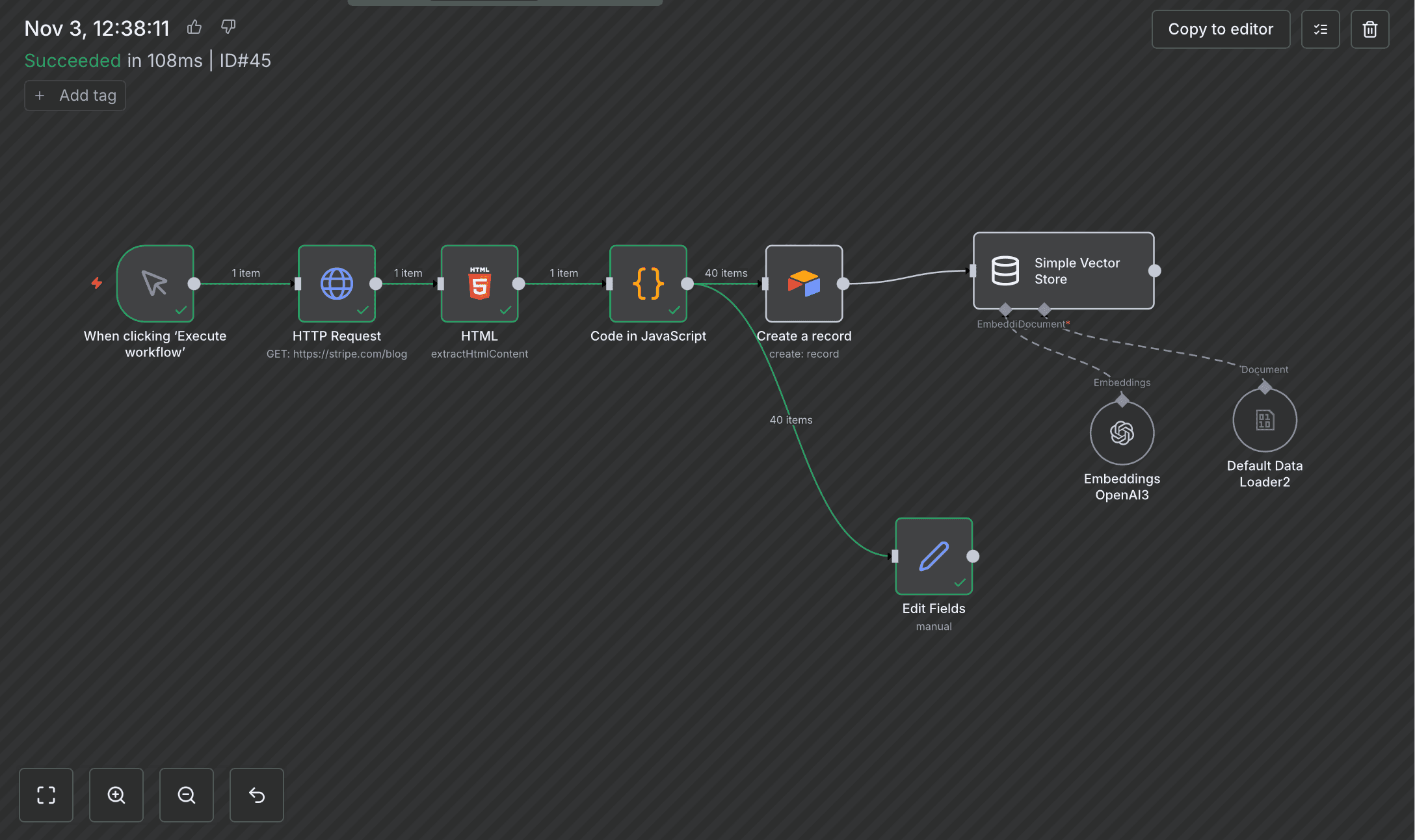
The Editor's View
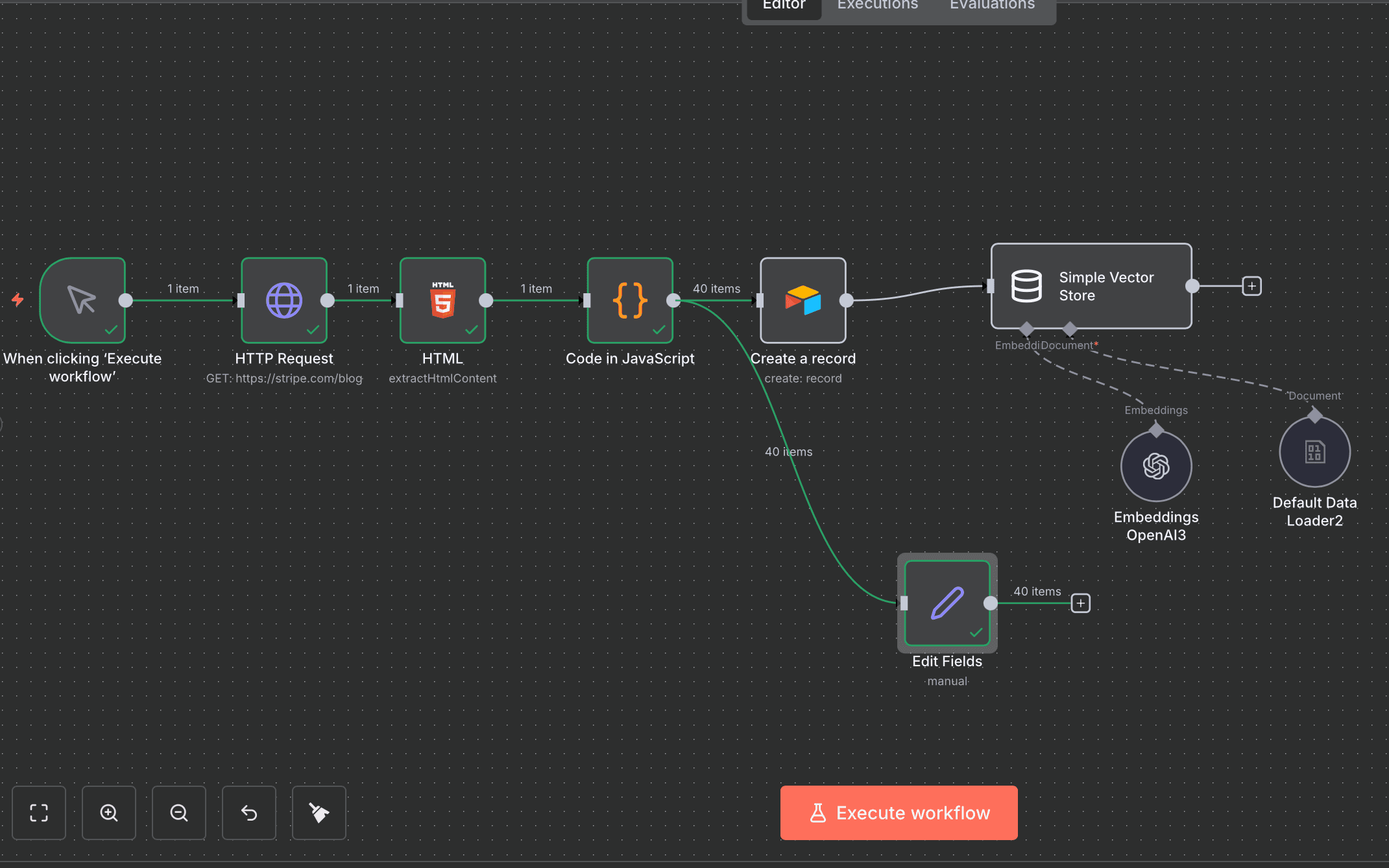
04 — Workflow Components
1. Content Retrieval
Nodes: Scheduler / Manual Trigger + HTTP Request
The workflow calls a public documentation URL to retrieve the raw HTML of a page.
2. HTML Parsing
Node: HTML Extract
CSS selectors extract the relevant parts of the page:
h1 as article title
h2, h3, and p elements as content sections
This removes navigation, banners, code formatting, and irrelevant elements.
3. Text Chunking
Node: Text Splitter
Content is split into overlapping text segments to preserve context integrity for semantic search.
- Chunk size: ~1,000 characters
- Overlap: ~150 characters
4. Embedding Generation
Node: OpenAI embeddings
Each chunk is converted into a numerical vector using an embedding model (text-embedding-3-small).
This enables semantic retrieval instead of keyword matching.
5. Data Storage
Nodes: Airtable + Vector Store
For each chunk, the process stores:
This ensures both human-readable data and machine-retrievable vector data.
05 — Result
The workflow calls a public documentation URL to retrieve the raw HTML of a page. The workflow automatically converts live documentation into a structured, searchable knowledge base that can power:
AI FAQ systems
Internal support bots
Developer assistants
Context-aware search
The system scales with new content and requires no manual intervention once deployed.
06 — Tools Used
n8n: workflow orchestration
OpenAI: embedding generation
Airtable: structured text storage
Vector storage engine: embedding indexing
CSS selectors + HTML parsing techniques
07 — Capabilities Demonstrated
RAG pipeline design
Automation architecture
Working with vector search logic
Data extraction and transformation
API integration and model configuration
Practical application of LLM infrastructure in no-code environments
08 — Next Steps
refine question extraction accuracy
improve automated formatting of chatbot responses
integrate confidence scoring for extracted FAQs
test pipeline on larger knowledge base dataset
09 — Learnings
This prototype validated the feasibility of automating FAQ extraction from knowledge bases. It highlighted key challenges around semantic question detection and structured output generation, informing the next iteration.